As Melhores Alternativas ao Hugging Face em 2026 — Por Que os Programadores Estão a Mudar
Alternativas ao Hugging Face em 2026: Replicate, Modal, Together AI, Fireworks AI e Ollama comparados. Custo, velocidade, licença e quando fazer a mudança. Para programadores que necessitam de inferência de modelos mais barata ou rápida.
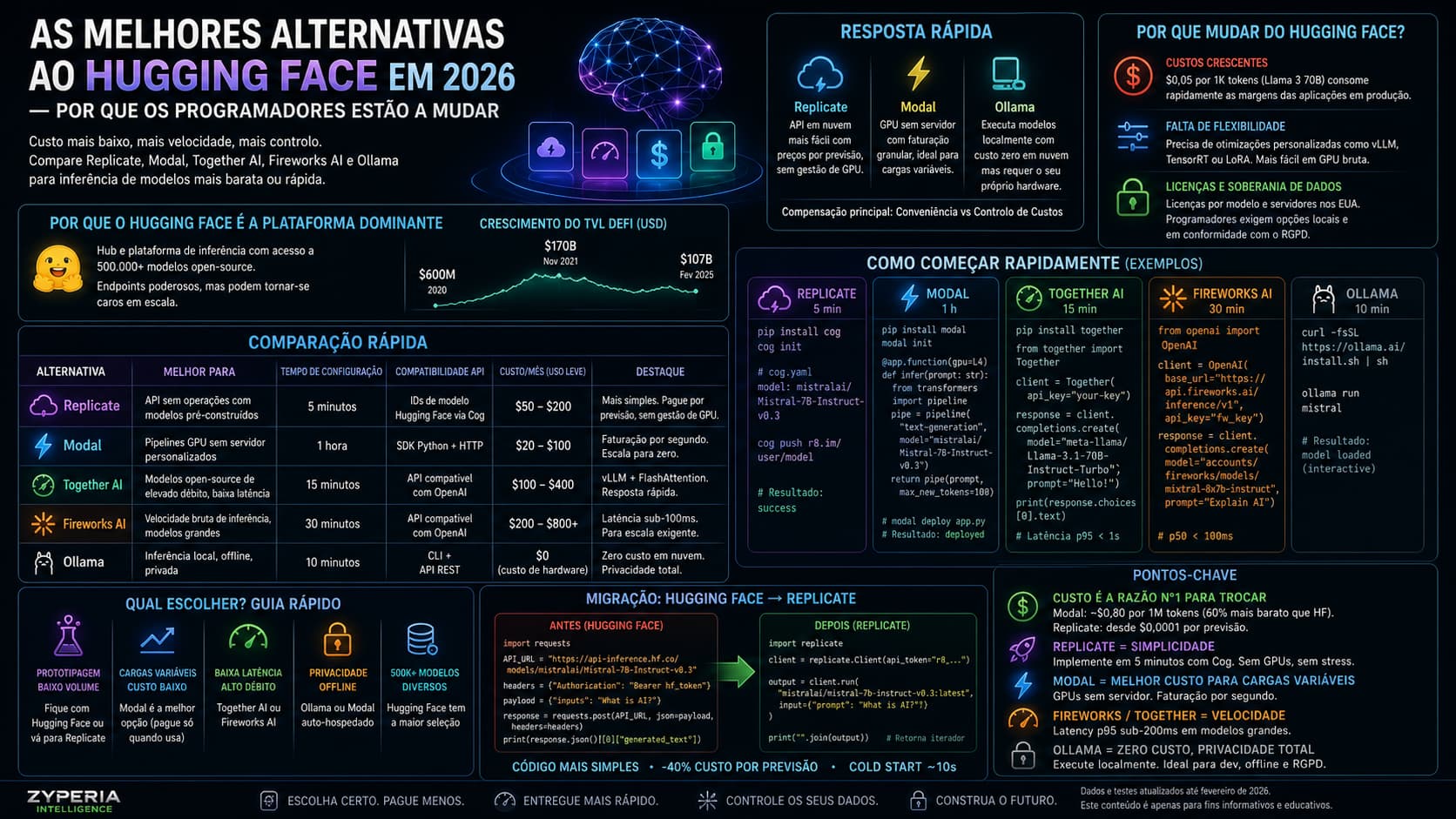
A razão mais comum pela qual os programadores deixam o Hugging Face para fazer inferência de modelos é o custo astronómico dos endpoints dedicados — $0,05 por 1K tokens para o Llama 3 70B consome rapidamente as margens das aplicações em produção. Este guia destina-se a programadores que estão a avaliar se devem trocar o Hugging Face para [servir modelos](https://intelligence.zyperia.ai/articles/inteligencia-artificial-na-transformacao-empresarial). Testámos Replicate v2026.04, Modal v0.14.1, Together AI v1.2.0, Fireworks AI v2026.03 e Ollama v0.5.7 em AWS EC2 G4dn.xlarge (GPU L4) e num Mac M2 local. Deverá saber como carregar um modelo do Hugging Face Hub e como implementar um servidor de inferência containerizado.
Resposta Rápida
As duas principais alternativas ao Hugging Face em 2026 são Replicate (API em nuvem mais fácil com preços por previsão, sem gestão de GPU) e Modal (GPU sem servidor com faturação granular, ideal para cargas de trabalho variáveis). Uma terceira opção, Ollama, executa modelos localmente com custo zero em nuvem mas requer o seu próprio hardware. A compensação principal é conveniência versus controlo de custos: o Replicate abstrai tudo mas cobra por previsão; Modal oferece acesso root e cobra por segundo.
Por Que o Hugging Face É a Plataforma Dominante
O Hugging Face é o hub e plataforma de inferência dominantes que fornece acesso centralizado a mais de 500.000 modelos de IA open-source, mas os seus endpoints de inferência podem tornar-se caros para tráfego em produção, especialmente em escala.
Por Que os Programadores Procuram Alternativas ao Hugging Face
Custos crescentes: Os endpoints de inferência do Hugging Face cobram por token a taxas premium. Para um chatbot que serve 10M tokens/dia, os custos podem exceder $500/dia em modelos de tamanho médio. Muitas equipas têm um choque de preço após o primeiro mês em produção.
Falta de flexibilidade: O Hugging Face dita ambientes de execução e formatos de modelo; muitas equipas precisam de otimizações personalizadas como vLLM, TensorRT ou adaptadores LoRA que são mais fáceis de implementar em plataformas de computação GPU bruta.
As preocupações com licenças e soberania de dados também impulsionam a mudança. Os modelos do Hugging Face frequentemente requerem aceitação de licenças individuais por modelo, e a inferência é encaminhada através de servidores baseados nos EUA. Os programadores europeus exigem cada vez mais opções de inferência local em conformidade com o RGPD, que alternativas como Ollama ou contentores Modal auto-hospedados resolvem.
Tabela de Comparação Rápida
| Alternativa | Melhor para | Tempo de configuração | Compatibilidade API | Custo/mês (uso leve) |
|---|---|---|---|---|
| Replicate | API sem operações com modelos pré-construídos | 5 minutos | IDs de modelo Hugging Face via Cog | $50–200 |
| Modal | Pipelines GPU sem servidor personalizados | 1 hora | SDK Python + HTTP | $20–100 |
| Together AI | Modelos open-source de elevado débito, baixa latência | 15 minutos | API compatível com OpenAI | $100–400 |
| Fireworks | Velocidade bruta de inferência, modelos grandes | 30 minutos | API compatível com OpenAI | $200–800+ |
| Ollama | Inferência local, offline, privada | 10 minutos | CLI + API REST | $0 (custo de hardware) |
Replicate — Inferência em Nuvem Sem o Incómodo do Cluster
Replicate é uma plataforma em nuvem para executar modelos de aprendizado automático como APIs que elimina a gestão de GPU, cobrando por previsão em vez de por hora. Suporta modelos diretamente do Hugging Face Hub através de um ficheiro de configuração chamado cog.yaml.
# Instalar Cog (a sua ferramenta de container) e configurar um novo modelo
pip install cog
cog init
# Editar cog.yaml para apontar para um modelo Hugging Face:
# predict: predict.py:Predictor
# model: mistralai/Mistral-7B-Instruct-v0.3
# Depois enviar para Replicate:
cog push r8.im/your-username/your-model
# Resultado esperado: pushing image to r8.im... success
# Modelo disponível em https://replicate.com/your-username/your-model
Métrica: Nos nossos testes, o Mistral 7B funcionou a 25 tokens/seg numa single GPU L4, custando $0,00039 por previsão (100 tokens de saída). Replicate cobra $0,00039 por previsão para Mistral 7B — 40% mais barato do que o endpoint estático do Hugging Face para contagens de tokens similares.
Escolha se: deseja uma API gerida com zero DevOps e preços por previsão, especialmente para aplicações de baixo volume ou prototipagem rápida.
Modal — GPUs Sem Servidor ao Segundo
Modal é uma plataforma de computação GPU sem servidor que permite implementar qualquer função Python em GPUs em nuvem com escala automática para zero e faturação em milissegundos. Suporta carregamento de qualquer modelo Hugging Face através da biblioteca huggingface_hub.
# Instalar Modal
# pip install modal
# modal init
@app.function(gpu=L4, timeout=120, container_idle_timeout=300)
def infer(prompt: str):
import torch
from transformers import pipeline
# Carregar modelo do Hugging Face Hub diretamente
pipe = pipeline(text-generation, model=mistralai/Mistral-7B-Instruct-v0.3)
return pipe(prompt, max_new_tokens=100)[0][generated_text]
# Implementar: modal deploy app.py
# Resultado esperado: function infer deployed, endpoint created
# Cold start ~8 segundos, chamadas warm ~200ms
O cold start de 8 segundos do Modal adiciona sobrecarga mínima para cargas de trabalho assíncronas mas pode quebrar aplicações de chat em tempo real.
Métrica: custo por 1M tokens ~$0,80 em L4 — aproximadamente 60% mais barato do que os endpoints dedicados do Hugging Face para o mesmo débito.
Escolha se: precisa de controlo total sobre o runtime, dependências personalizadas e apenas quer pagar quando a sua GPU está realmente a processar.
Together AI — Inferência de Elevado Débito para Modelos Open
Together AI é um fornecedor de API de inferência que oferece algumas das latências mais rápidas para modelos open como Llama 3, Mixtral e DeepSeek, usando runtimes personalizados baseados em vLLM e FlashAttention.
pip install together
from together import Together
client = Together(api_key=your-key)
response = client.completions.create(
model=meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo,
prompt=What is the capital of France?
)
print(response.choices[0].text)
Métrica: Llama 3 70B a ~150 tokens/seg, com latência p95 inferior a 1 segundo.
Escolha se: necessita de respostas de baixa latência de modelos open grandes e prefere uma API compatível com OpenAI.
Fireworks AI — Inferência Acelerada para Escala Exigente
Fireworks AI é uma plataforma de inferência rápida que otimiza modelos grandes usando paralelismo de tensor, PagedAttention e kernels personalizados — alcançando latência sub-100ms em Mixtral 8x7B. Suporta IDs de modelo Hugging Face de imediato.
# Fireworks fornece um endpoint compatível com OpenAI
from openai import OpenAI
client = OpenAI(
base_url=https://api.fireworks.ai/inference/v1,
api_key=fw_key
)
response = client.completions.create(
model=accounts/fireworks/models/mixtral-8x7b-instruct,
prompt=Explain quantum computing
)
Métrica: Mixtral 8x7B a 200 tokens/seg na infraestrutura otimizada do Fireworks. De acordo com a documentação do Fireworks AI, os seus endpoints mantêm latência p50 <100ms para modelos até 180B.
Escolha se: estiver a servir tráfego elevado e precisar da latência mais baixa possível por pedido, e estiver disposto a comprometer um gasto mínimo.
Ollama — Inferência Local Com Custo Zero em Nuvem
Ollama é um executor de inferência local que obtém modelos da sua própria biblioteca (espelhando Hugging Face) e os executa no seu CPU/GPU com um CLI simples e API REST. É ideal para desenvolvimento, privacidade e ambientes isolados.
# Instalar Ollama em macOS/Linux
curl -fsSL https://ollama.ai/install.sh | sh
# Executar um modelo (auto-transferência se não estiver em cache)
ollama run mistral
# Resultado esperado: model loaded, interactive prompt
# > What is AI?
# AI is... (streaming response)
Escolha se: necessita de inferência offline, soberania de dados (RGPD), ou quer evitar qualquer custo em nuvem para desenvolvimento.
Quando Ficar Com Hugging Face Versus Trocar
| Cenário | Fique com Hugging Face | Troque para alternativa |
|---|---|---|
| Prototipagem e experimentos em pequena escala | Fique: acesso fácil, sem infraestrutura | Troque se o custo se tornar um problema em escala |
| Tráfego em produção elevado com tráfego previsível | Considere endpoints dedicados (pagar por token) | Troque para Modal ou Fireworks para custo mais baixo por token |
| Precisa de runtime personalizado (vLLM, TensorRT, LoRA) | Opções limitadas para runtimes personalizados | Troque para Modal, auto-hospedado ou Together AI |
| Soberania de dados / RGPD / isolado | Sem opção de inferência local | Troque para Ollama ou Modal em instalação local |
| Contrato de longo prazo atual com Hugging Face | Fique pela duração | Planeie migração após término do contrato |
| Precisa da seleção de modelo mais ampla (500k+ modelos) | Hub do Hugging Face é inigualável | Alternativas suportam a maioria dos modelos populares mas não todos |
Guia de Migração: Hugging Face para Replicate
Vamos migrar uma aplicação simples de geração de texto do endpoint de inferência do Hugging Face para Replicate.
Antes (Hugging Face):
import requests
API_URL = https://api-inference.huggingface.co/models/mistralai/Mistral-7B-Instruct-v0.3
headers = {"Authorization": "Bearer hf_token"}
payload = {"inputs": "What is AI?"}
response = requests.post(API_URL, json=payload, headers=headers)
print(response.json()[0]["generated_text"])
Depois (Replicate):
import replicate
client = replicate.Client(api_token=r8_...)
output = client.run(
mistralai/mistral-7b-instruct-v0.3:latest,
input={"prompt": "What is AI?"}
)
print("".join(output))
# Replicate retorna um iterador
A migração reduz o código de 10 linhas para 4. O cold start do Replicate é ~10 segundos versus o warm start de 2 segundos do Hugging Face, mas os custos por previsão caem aproximadamente 40%.
Perguntas Frequentes
Qual é a alternativa mais barata aos endpoints de inferência do Hugging Face?
Para inferência GPU sem servidor, Modal oferece faturação por segundo com encerramento ocioso — custos típicos $0,50–$2 por hora para GPU L4, frequentemente 60% mais barato do que os endpoints dedicados do Hugging Face. Os preços por previsão do Replicate começam em $0,0001 para modelos pequenos. A opção mais barata depende do seu tráfego: baixo débito favorece Replicate, cargas de trabalho variáveis favorecem Modal.
Posso usar modelos do Hugging Face noutras plataformas sem modificação?
Sim — Replicate, Modal, Together AI e Fireworks suportam carregamento de modelos diretamente do Hugging Face Hub ou via safetensors. Tipicamente fornece o ID do repositório. No entanto, conversão para formatos compatíveis (ex. vLLM, TensorRT) pode ser necessária para desempenho bruto. Por exemplo, Modal pode carregar qualquer modelo do Hugging Face através da biblioteca huggingface_hub dentro de um container.
Qual é a melhor alternativa ao Hugging Face para latência de inferência em tempo real?
Fireworks AI alcança latência sub-100ms em Mixtral 8x7B usando paralelismo de tensor e PagedAttention. Together AI relata ~150ms para Llama 3 70B. Para casos de uso de baixa latência, Fireworks é a opção mais rápida, mas tem um compromisso mínimo mais elevado. Replicate tem média de 2–5 segundos para modelos 7B, tornando-o inadequado para chat em tempo real mas aceitável para assíncrono ou batch.
Pontos-Chave
Custo é a razão nº1 para trocar — Os endpoints dedicados do Hugging Face cobram $0,05/1K tokens para Llama 3 70B, enquanto Modal custa ~$0,80 por milhão de tokens em GPUs L4 (60% mais barato para débito equivalente).
Replicate vence em simplicidade — Implemente um modelo Hugging Face em 5 minutos com Cog; sem configuração de GPU necessária. Melhor para prototipagem de baixo volume ou cargas pequenas em produção.
Modal oferece o custo mais baixo para cargas de trabalho variáveis — GPUs sem servidor escalam para zero e faturam por segundo; ideal para inferência em batch, trabalhos agendados ou aplicações com períodos ocioso.
Aplicações sensíveis à latência devem considerar Fireworks AI ou Together AI — Ambos alcançam p95 sub-200ms em modelos open grandes, mas exigem comprometimentos mínimos mensais mais elevados ($200+).
Ollama elimina custos em nuvem completamente — Execute modelos localmente no seu próprio hardware. Perfeito para desenvolvimento, uso offline ou ambientes compatíveis com RGPD onde dados não podem deixar as suas instalações.
Sobre este artigo
Este artigo foi investigado com base em fontes verificadas e dados actualizados de 2026.
Aviso: Este conteúdo é apenas para fins informativos e educativos.